I'm working on my master's in computer science, and this fall I took my first course: Machine Learning for Trading. I picked it partially out of interest and partially out of pragmatics: since I haven't been in school for many years and I've never worked full time while in school, I only considered courses that took 10 hours per week, rather than the 20-30 for the other data-related courses.
I was also curious about trading, and I'll admit I went in biased: were hedge funds as soulless and unethical as I'd heard? How does this stock market thing actually work? And what sorts of machine learning techniques work best on the ultimate random walk?
Here are some things I learned. This post will probably make more sense to you if you're a data scientist, but it should be skimmable even if you don't know your random forests from your black-red trees.
Reinforcement learning is kind of astounding
As it turns out, you can apply lessons learned from physical robots to stock trading. A technique called reinforcement learning (RL) works for both, and is remarkably flexible. I hadn't used RL in practice yet and understood it only at a high level, so it was really instructive to go through concrete examples. We started in a virtual world, on a 10x10 board with a lonely robot who moved through a harsh landscape in search of the goal. Thwarting her were long walls and a quicksand pit. Every move that she wasn't in the goal was agony, sapping her one point. Quicksand cost her -100 points. And getting to the goal got her only one measely positive point. Interestingly, that's plenty to motivate our little robot.
She starts her run, randomly bouncing around the board until she happens to stumble on the goal. It's been painful, but she's learned a lot about what's worked and what hasn't. She starts over and tries again, still randomly. Gradually we decrease the rate of randomness and she's allowed to use the knowledge she's learned about the board. The quicksand is such a hazard (and her wheels are a little hard to control, we've added randomness there too) so she'll be cautious and stop trying the side of the board with the quicksand entirely.
If you've ever watched a piano player go from an awkward Chopsticks to an elegant Moonlight Sonata, this will sound familiar. It's more similar to mammalian learning than you might think. When we start, our neural circuits are inefficient and our movements uncoordinated. As we practice, the right connections are reinforced and the wrong ones ignored, and our movements get more smooth. To be sure, there are major differences. Our robot doesn't understand concepts like "walls" and "quicksand." She only knows that when she's on square 44, she should go north because that has historically resulted in less pain. That's it. But she can do a surprising amount with just that. This is a really powerful, flexible machine learning technique.
We adjusted a few other parameters about our learner. Instead of just learning from the next step, we had them learn from the next possible steps from there as well. We used a learning coefficient to adjust the relative weight between step n and step n+1. This also allows the goal value to propagate back through the map, and my physics brain made me think of a vector field—it was almost like at each point in the map there was an arrow pointing the robot in the best direction. We also implemented a technique called dyna, which allows the robot to learn faster in situations where it is expensive to take steps in the real world. She "hallucinates" possible outcomes based on the experiences she's seen so far, and updates her transition tables according to that probability distribution.
In doing this, I learned some interesting things about random sampling performance—I coded up this beautiful algorithm to track the probability distributions and then sample from them, but it was too slow to pass the course's timeout tests. Much to my chagrin, it was much, much faster to just save every single experience tuple in memory and then randomly sample those. This is an unsustainable memory strategy in bigger systems.
Our next project applied reinforcment learning to the stock market. The first challenge is mapping the price and volume data to a "board" like we did for our robot. To do that, we had to discretize the prices into discrete states. We used indicators, which are scores we compute to quantify the current state of stocks. These indicators and states were designed in such a way that at any point in time, the stock fell into a well-defined state. In the robot's grid world, we described her state as "square 44" which was the 4th row and 4th column. For stocks, I created states like "012" which meant that the first indicator had a value of 0, the second had a value of 1 and the third had a value of 2. 0, 1, and 2 are essentially low, medium, and high. I expected more states to be more predictive, but using three levels per indicator (so 333 = 27 states) worked best. Perhaps they were overfitting less.
The second challenge is defining actions and resulting rewards. For stocks, this maps very neatly: the reward is the money you earn from trading, and our action options are to hold, buy, or sell. The resulting Q-learner trading bot was reasonably successful, earning hypothetical money even during the rocky years of 2007-2008.
I've started looking for places around the company where q-learning could be useful. The e-commerce team has some thoughts around optimizing our email marketing: I can see how the customer's place in the conversion funnel would map to a state, sending various emails would be our actions, and clicking or buying would be rewards.
I also got a puppy while taking this course and did a lot of thinking about how dog training relates to reinforcement learning, but that's a topic for another post!
Random Forests from scratch
I'd used random forests before in my day job, but had never coded one up from scratch just using Numpy. It felt a bit like I was back in the Recurse Center, which believes the best way to deeply understand how something works is to build one yourself.
We used a very "numpy" data structure to hold the data. everything in a dataframe: one row per decision node or leaf node. The root node was in the 0th row, and then the entire left tree was in the next N rows, then the entire right tree. Each subtree had the same structure as the main tree so we created the trees recursively. The columns held the split criteria, split row, and the index of which row to go to for right or left.
There are so many different data structures you could use for building trees. In my current course, Artificial Intelligence, we're building our random forests with a custom DecisionNode class that has pointers to a left and right tree. So it's essentially a linked list, but with a tree structure—a "linked tree"? I find this approach to be more intuitive and less bug-prone than the dataframe approach, but the dataframe is really, really fast and simpler to debug.
How to use numpy directly.
Numpy is a Python library for doing efficient computation on vectors of numbers. Pandas is a Python library that builds on numpy by offering convenience methods. For instance, a Python DataFrame is a dictionary of numpy arrays, plus extremely helpful class methods added. I mean, just look at its read_csv method! You can do fairly sophisticated data cleaning in just one line of code.
I use pandas all the time in my work but hadn't really looked under the hood to do much with numpy directly, and I was really interested to dig a layer deeper. We used numpy directly for our first few projects. I don't think this will change my day-to-day work much, but understanding numpy helps me understand why pandas is architected the way it is, and I am now much more confident applying numpy's many useful vectorizing functions. I also suspect it will come in handy if I need to optimize pandas code, as numpy can e.g. have less memory overhead. It's also useful for matrix operations where you just want to index the data by row and column.
That Pandas was really written specifically for trading
Pandas is a Python library for data manipulation and analysis, and I use it all the time for my work. Wes McKinney wrote it while working at AQR Capital Management. Before this course, I knew intellectually that it had been created by a trader, but after using it for trading I really viscerally see it. It had a bunch of the functions I needed built in and the timeseries handling was really thoughtful. Rather seeing it as a general-purpose tool that can be used for trading, I now see it as a trading tool we're using for other things.
How to fool yourself with sloppy machine learning
You can screw up your trading algorithm by committing classic machine learning errors, like overfitting or getting too excited about insample performance. There are also subtle problems specific to trading that were new to me. For instance, you can get in trouble backtesting your trading strategy with the S&P 500. Today's S&P 500. Your strategy will do great historically, but you've got survivorship bias: you're only including the companies that didn't die. By definition they're the top performers, so of course your strategy did great. Testing on historical S&P 500 companies brings your strategy back down to earth.
There are a few other interesting pitfalls, like accidentally training on future information, ignoring the market impact of your own trades, or proposing buying $10M in a $1M company. Also, some strategies can perform very differently depending on which particular day you happen to start trading! Wild. You can read about these in more detail here.
What those indicators in Fidelity mean!
I was checking my investment account the other day and for the first time really looked at these graphs:
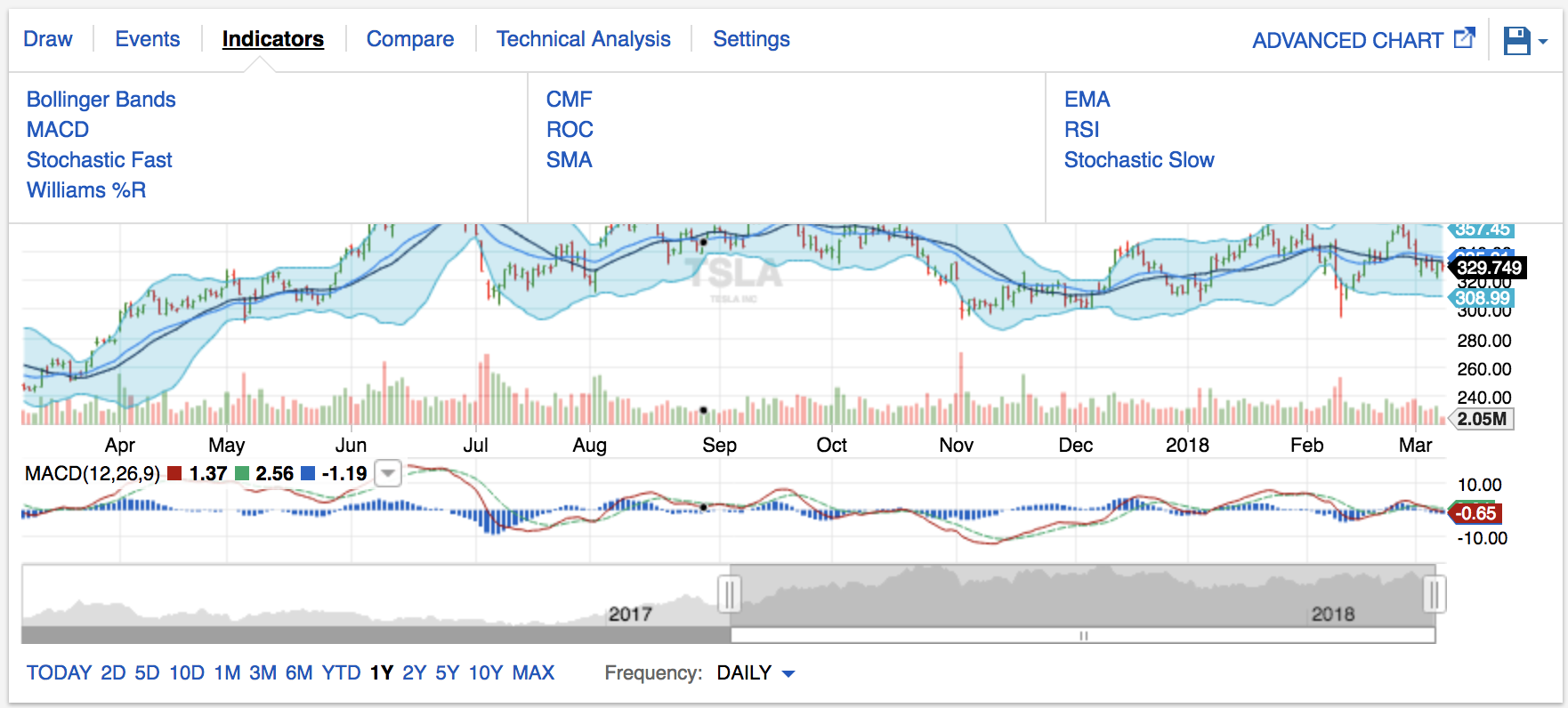
I now know exactly what these indicators are, and I've coded up RSI, MACD, and Bollinger Bands from scratch! Pretty cool to see coursework in real life.
How hedge funds work: who can invest in them, their incentive structures, how they go about making money, some pitfalls of underregulation, and thoughts on ethics
Warren Buffet uses an approach called fundamental analysis, where his team learns as much as possible about the business and the sector before investing for the long term. Many (but not all) hedge funds try the opposite: they do technical analysis, looking only at the price and volume information, and then trade very very fast. They're essentially looking at timing and patterns in the stock market and trying to spot trends before anyone else does.
But consider for a minute how many eyes are on the stock market at all times. If there's a sudden change, many other people will see it too. Is it even possible to win? The Efficient Market Hypothesis says no. The market is efficient, and that means that any potential advantages will be acted on very quickly. So how do hedge fund managers get consistently rich?
They set up very clever incentive structures. They traditionally take a "two and twenty" cut: 2% of the assets under their management, and 20% of any profits made. So if the market goes up, they make tremendous money. If the market goes down, they still make 2% on a large asset pool anyway. Only investors feel the pain of a down market. So they're strongly incentivized to take aggressive risks, since there's structurally no downside for them.
But what about the investor. Don't they have a lot to lose? Yes, in exchange for potentially enormous profits, they take on significant risk. In order to become an investor you need to have a very high net worth, and hedge funds are mostly unregulated beyond that. For instance, they have no obligation to share information with investors the same way mutual funds do. I guess regulators figure that if you have a high enough net worth, you can afford to lose a ton of money in a risky investment so why not?
The ethics are murkier than I thought
I went in with a vague anti-finance stance. My college and social circles generally disapprove, and I'd absorbed that stance. But I didn't really knowing how finance works, and I wanted to have a more informed opinion. I expected to be able to come out of this course able to defend that stance with Facts and Figures and Knowledge. But it is less clear than I thought.
Two opinions didn't change: regulation is absolutely essential to not letting greed crash the economy (this course did take us on a brief, technical tour of the 2008 crash). And it's a field that is by definition removed from humans. But it's very hard for me to make the case that trading on its own is actually unethical.
At its core, it's using programming and math on publicly available tickers to try to beat other people to a good deal. And it makes money for pension funds, right? It can only make rich people richer, so if you believe we have a moral obligation to redistribute wealth you'd probably be opposed. But in practice, most funds lose money, so maybe you'd be in favor. The broader regulation environment is (unethically) set up to advantage financial institutions over individual persons, as we saw in the crash, but I find it really hard to argue that most individual funds are acting unethically. Regardless, this is not what I want to spend my limited time on earth working on. Sorry, recruiters!
(I'm very interested in discussing this further. The course did almost zero discussion of the ethics of trading, so I feel like I have a lot to learn about it)
How to be an efficient student.
I was always pretty good at school, in that I got good grades and went to a top college. But I was thorough and linear, struggled with procrastination, and worked too many hours. I bought and read through this book which is all about how to do well without working all the time. It's aimed at the undergraduate level, but it's made a big difference already. It helped me realize that I could skip literally all the reading across all three textbooks for this course, as the material was entirely covered in the lectures. I only wish I'd had it in hand during college!